Author: Godofredo Fdez.
Add new comment
A vueltas con los sistemas de codificación
Los que llevamos trabajando con GNU/Linux unos años (casi un par de decadas ya) hemos sufrido los inconvenientes asociados al soporte de distintos juegos de caracteres. En los inicios las distribuciones no traían por defecto activado el soporte del sistema de codificación ISO-8859-1, por lo que conseguir nuestros caracteres con tilde ("jamón") era imposible, y no hablemos de conseguir nuestra letrita española: "ñ".
Así, era tarea obligada conseguir que las diversas aplicaciones, y todo el entorno, soportara ese juego de caracteres. Tras algunos ajustes en diversos ficheros de configuración la sonrisa brillaba en nuestra cara cuando conseguíamos, al fin, escribir sin problemas en nuestro expresivo idioma.
Uno de esos ajustes aún pervivía en mis ficheros de configuración: mi ".emacs" incluía las siguientes líneas:
(custom-set-variables
'(current-language-environment "Latin-9")
'(default-input-method "latin-9-prefix")
'(current-language-environment "Latin-9")
'(default-input-method "latin-9-prefix")
)
Esto provocaba que, aún hoy cuando el sistema de codificación por defecto y anchamente utilizado (y recomendado) es utf-8, mi genial editor emacs seguía utilizando el sistema de codificación de antaño, lo que provocaba problemas de visualización posteriores de esos ficheros con otras herramientas que, automáticamente, querían utilizar el sistema de codificación más actual: había un choque entre el antiguo iso-8859-1 y el nuevo utf-8. Podéis ver un ejemplo de lo que ocurría en la siguiente figura:
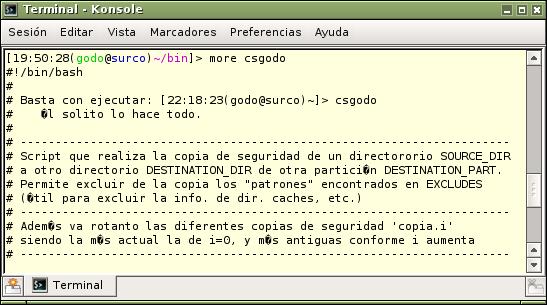
Tocaba, pues, investigar como convertir los ficheros con sistema de codificación antiguo al nuevo. ¿Cuál es el sistema de codificación antiguo en el que están codificados esos ficheros que se ven con extraños caracteres? ¿Cómo podemos saberlo? Fácil, abrimos con emacs el fichero, pulsamos Ctrl-H Shift(Mayús)-C y aparece la siguiente frase en la línea de comandos del editor: "Describe coding system (default current choices): ", pulsamos "Intro" y obtenemos algo parecido a esto:
Coding system for saving this buffer:
1 -- iso-latin-1-unix
1 -- iso-latin-1-unix
Default coding system (for new files):
u -- mule-utf-8 (alias: utf-8)
Coding system for keyboard input:
nil
Coding system for terminal output:
u -- utf-8 (alias of mule-utf-8)
Defaults for subprocess I/O:
decoding: u -- mule-utf-8 (alias: utf-8)
encoding: u -- mule-utf-8 (alias: utf-8)
Fijaos en el primer par de líneas. El fichero está siendo grabado en el sistema de codificación en el que ha sido leído, en nuestro caso: iso-latin-1-unix. Por tanto, el proceso de conversión ha de ser de iso-latin-1-unix a utf-8.
Bien, instalamos una pequeña y útil herramienta (al más puro estilo UNIX):
[19:51:17(root@surco)/home/godo/bin]> apt-get install konwert
Leyendo lista de paquetes... Hecho
Creando árbol de dependencias
Leyendo la información de estado... Hecho
Se instalarán los siguientes paquetes extras:
konwert-filters
Paquetes sugeridos:
konwert-dev
Se instalarán los siguientes paquetes NUEVOS:
konwert konwert-filters
0 actualizados, 2 se instalarán, 0 para eliminar y 0 no actualizados.
Necesito descargar 278kB de archivos.
Se utilizarán 2122kB de espacio de disco adicional después de esta operación.
¿Desea continuar [S/n]?
Des:1 http://mirror.switch.ch stable/main konwert-filters 1.8-11.2 [230kB]
Des:2 http://mirror.switch.ch stable/main konwert 1.8-11.2 [47,8kB]
Descargados 278kB en 1s (201kB/s)
Reading package fields... Done
Reading package status... Done
Retrieving bug reports... Done
Parsing Found/Fixed information... Done
Seleccionando el paquete konwert-filters previamente no seleccionado.
(Leyendo la base de datos ...
166593 ficheros y directorios instalados actualmente.)
Desempaquetando konwert-filters (de .../konwert-filters_1.8-11.2_all.deb) ...
Seleccionando el paquete konwert previamente no seleccionado.
Desempaquetando konwert (de .../konwert_1.8-11.2_i386.deb) ...
Procesando disparadores para man-db ...
Configurando konwert-filters (1.8-11.2) ...
Configurando konwert (1.8-11.2) ...
[19:51:38(root@surco)/home/godo/bin]> apt-get clean
[19:51:42(root@surco)/home/godo/bin]> exit
Leyendo lista de paquetes... Hecho
Creando árbol de dependencias
Leyendo la información de estado... Hecho
Se instalarán los siguientes paquetes extras:
konwert-filters
Paquetes sugeridos:
konwert-dev
Se instalarán los siguientes paquetes NUEVOS:
konwert konwert-filters
0 actualizados, 2 se instalarán, 0 para eliminar y 0 no actualizados.
Necesito descargar 278kB de archivos.
Se utilizarán 2122kB de espacio de disco adicional después de esta operación.
¿Desea continuar [S/n]?
Des:1 http://mirror.switch.ch stable/main konwert-filters 1.8-11.2 [230kB]
Des:2 http://mirror.switch.ch stable/main konwert 1.8-11.2 [47,8kB]
Descargados 278kB en 1s (201kB/s)
Reading package fields... Done
Reading package status... Done
Retrieving bug reports... Done
Parsing Found/Fixed information... Done
Seleccionando el paquete konwert-filters previamente no seleccionado.
(Leyendo la base de datos ...
166593 ficheros y directorios instalados actualmente.)
Desempaquetando konwert-filters (de .../konwert-filters_1.8-11.2_all.deb) ...
Seleccionando el paquete konwert previamente no seleccionado.
Desempaquetando konwert (de .../konwert_1.8-11.2_i386.deb) ...
Procesando disparadores para man-db ...
Configurando konwert-filters (1.8-11.2) ...
Configurando konwert (1.8-11.2) ...
[19:51:38(root@surco)/home/godo/bin]> apt-get clean
[19:51:42(root@surco)/home/godo/bin]> exit
Miramos su página de manual:
[19:51:43(godo@surco)~/bin]> man konwert
Y procedemos a la conversión:
[19:54:19(godo@surco)~/bin]> konwert iso1-utf8 csgodo -o csgod
Observamos que el filtro que hay que utilizar (obtenido de la página de manual) para llevar a cabo la conversión que nos interesa se llama iso1-utf8, el fichero de entrada, el origen que queremos convertir, es csgodo, y el de salida, ya convertido a utf-8 es csgod. Lo vemos con un visor: more, less, etc. Comprobamos que está bien y sobrescribimos nuestro fichero original:
[19:55:20(godo@surco)~/bin]> mv csgod csgodo
mv: ¿sobreescribir «csgodo»? (s/n) s
[19:55:31(godo@surco)~/bin]>
mv: ¿sobreescribir «csgodo»? (s/n) s
[19:55:31(godo@surco)~/bin]>
A continuación podéis observar el resultado tras la conversión:
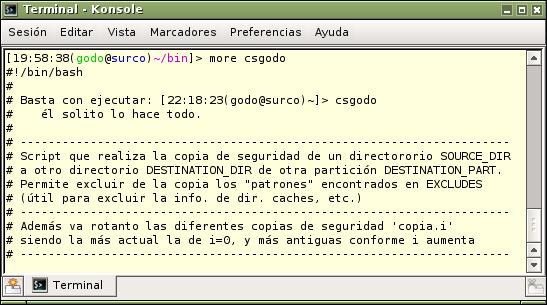
¡Objetivo conseguido!
Por último, para comprobar que tenéis vuestro entorno configurado para trabajar con el sistema de codificación utf-8 por defecto, basta hacer:
[20:59:47(godo@surco)~]> locale
LANG=es_ES.UTF-8
LANGUAGE=es_ES.UTF-8
LC_CTYPE="es_ES.UTF-8"
LC_NUMERIC="es_ES.UTF-8"
LC_TIME="es_ES.UTF-8"
LC_COLLATE="es_ES.UTF-8"
LC_MONETARY="es_ES.UTF-8"
LC_MESSAGES="es_ES.UTF-8"
LC_PAPER="es_ES.UTF-8"
LC_NAME="es_ES.UTF-8"
LC_ADDRESS="es_ES.UTF-8"
LC_TELEPHONE="es_ES.UTF-8"
LC_MEASUREMENT="es_ES.UTF-8"
LC_IDENTIFICATION="es_ES.UTF-8"
LC_ALL=
[20:59:48(godo@surco)~]>
LANG=es_ES.UTF-8
LANGUAGE=es_ES.UTF-8
LC_CTYPE="es_ES.UTF-8"
LC_NUMERIC="es_ES.UTF-8"
LC_TIME="es_ES.UTF-8"
LC_COLLATE="es_ES.UTF-8"
LC_MONETARY="es_ES.UTF-8"
LC_MESSAGES="es_ES.UTF-8"
LC_PAPER="es_ES.UTF-8"
LC_NAME="es_ES.UTF-8"
LC_ADDRESS="es_ES.UTF-8"
LC_TELEPHONE="es_ES.UTF-8"
LC_MEASUREMENT="es_ES.UTF-8"
LC_IDENTIFICATION="es_ES.UTF-8"
LC_ALL=
[20:59:48(godo@surco)~]>
Si no tenemos esos locales en nuestro sistema podemos cambiar los que actualmente tengamos haciendo uso, como root, del siguiente comando:
[21:02:40(root@surco)/home/godo]> dpkg-reconfigure locales
Nos aparecerá una lista, nos movemos por ella con "Av Pág / Re Pág" o con los cursores, seleccionamos/deseleccionamos con la barra espaciadora, y cuando tengamos lo que queremos pulsamos "Tab" y nos vamos hasta "Aceptar". Pulsamos "Intro".
Y, claro está, no olvidéis borrar del fichero de configuración de emacs (~/.emacs) las líneas que mencionaba más arriba. Desde la versión 22 emacs es capaz de adaptarse a lo configurado en nuestro entorno.
Salud.
Clasificado en artículos de:
- Add new comment
- 8711 reads